Obsidian Metadata
| source | https://alearningjourney.substack.com/p/what-i-learned-from-ai-evals-for |
| author | Nicholas Wagner, Hamel Husain |
| published | 2025-08-23 |
| description | And why I recommend you take the next class |
And why I recommend you take the next class
At the beginning of July, I came across a blog post from Hamel Husain and Ben Clavié arguing that we should “Stop Saying RAG Is Dead”. In one of the linked pages, Hamel mentioned he was teaching an upcoming course with Shreya Shankar called AI Evals for Engineers and PMs. Hamel and Shreya both have stellar AI industry resumes and effusive reviews of their prior teaching. I happened to be launching Learning Journey AI right around then and knew a lot of AI evaluation was coming to my life, so I signed up. In this post, I will give my main takeaways from the course and put them in the context of someone who has dealt a lot with AI in government and is now moving into education.
Why Evaluation Matters
I have seen AI systems from a variety of different perspectives in academia, government, and the private sector. It was common years ago and even more common now to find shoddy evaluation practices behind a whole host of claims about machine learning/AI performance. Claims that things will or won’t be possible with AI based on a statistically insignificant number of samples, claims that performance in some paper will generalize when it is the result of overfitting to the test set, claims that one product is better than another for some application based on anecdotes or benchmark scores that lack validity for the application, claims the new RAG system hallucinates too much when the information retrieval step has not even been evaluated separately, etc. The result is mass confusion, a trough of disillusionment, and lots of money being wasted on tools trying to fix problems when the source of the problems is not even correctly identified!
Shreya and Hamel point out that evaluation-driven development not only helps you figure out how an AI system is performing on some task, it makes it obvious what people are trying to do and why the system is not working for them, which makes it easier to develop improvements.
As for what a good evaluation flow looks like, see this diagram Shreya and Hamel shared in their first lesson. This sort of iterative cycle would not be unfamiliar to the many people in the DoD I heard talk about OODA loops or DevSecOps.
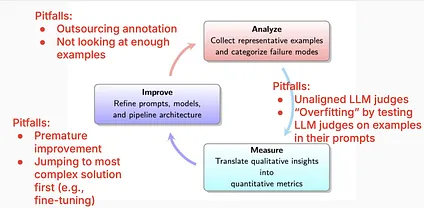
The core evaluation lifecycle from the first lecture along with pitfalls along the way.
Like many things in tech adoption, the pitfalls we should worry about stem from valuing shiny tools over solving actual problems. Take the time to make sure you are actually making your users’ lives better and don’t rush to implement what you saw recommended in a tweet. This is definitely something that should be communicated to people considering adopting AI.
Three Gulfs
There are three core challenges you tackle in evaluating modern AI systems: the Gulf of Comprehension, the Gulf of Specification, and the Gulf of Generalization. Each was defined in terms of a question that evaluation should answer:
- Gulf of Comprehension
- Can we understand our data and how our models and pipelines actually behave?
- Gulf of Specification
- Can we translate our intent into precise, unambiguous prompts and multi-step pipelines?
- Gulf of Generalization
- Will our model or pipeline perform reliably on new, unseen data?
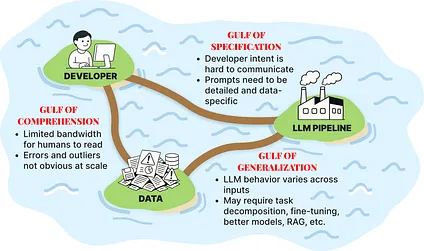
Slide from Hamel Husain & Shreya Sankar’s AI Evals for Engineers and PMs depicting three “gulfs” in LLM product work as islands linked by bridges. Left island “DEVELOPER” shows a person at a computer; lower-left island “DATA” shows piles of papers with a warning symbol; right island “LLM PIPELINE” is a factory. Red callouts: Gulf of Comprehension — “Limited bandwidth for humans to read”; “Errors and outliers not obvious at scale.” Gulf of Specification — “Developer intent is hard to communicate”; “Prompts need to be detailed and data-specific.” Gulf of Generalization — “LLM behavior varies across inputs”; “May require task decomposition, fine-tuning, better models, RAG, etc.”
Each of these gulfs requires a different skillset. Comprehension involves making sense of large amounts of data like a data scientist/domain expert, specification is more of a managerial challenge, and generalization is closest aligned with what is commonly called AI engineering. I think seeing evaluation broken down this way both illustrates why it is so important but also why it feels neglected: the sexy part is only one third of the work!
Draw upon existing science
There is nothing new under the sun when it comes to analyzing qualitative data. One of the first concepts we had explained was the three-steps for error analysis.
- Gathering Data: Ideally data from real users, but can also use synthetic data designed to mimic the diversity of real data (e.g. varying ambiguity, task, user persona, verbosity, etc.).
- Open Coding: Read traces and apply descriptive labels to find failure patterns.
- Axial Coding: Cluster those labels into a structured taxonomy of failure modes.
It does not seem like anything magical, but doing this with 100 samples will point the way to what is going right and wrong with your system. Several students complained that doing this properly would take a lot of subject matter expert or PM time. This is annoying, but true! Evaluation tools can lessen this burden, but they cannot remove it completely.
Collaborative error analysis came up as well. It is quite common in government to have multiple stakeholders weigh in on what constitutes success for an AI system, unlike in many startups where one person can quickly make executive decisions. For those who hate meetings, I regret to report that the recommended solution for generating rubrics was iterative alignment sessions. One important technical point: don’t rely on raw percent agreement! Statistically correct for chance inter-annotator agreement using Cohen’s Kappa.
Move from qualitative to quantitative with engineering controls
After coming up with axial codes in the analysis step, measurement is about turning that qualitative insight into quantitative data. Doing this efficiently requires automation. There are two main kinds:
- Programmatic evaluators: Code-based checks that are fast and deterministic.
- Examples: If a model says a tool is being used, does that tool exist in the list of known tools the model has access to? If code is being generated, does it pass a syntax validity check? Do alleged quotes from sources actually exist in them?
- LLM-as-judge: Using an LLM to evaluate subjective or nuanced criteria.
- Examples: Does the generated summary include all relevant details from the source text? Is the tone of the generated content appropriate for the task?
Programmatic evaluators are preferred because of their speed and consistency, but sometimes LLM-as-judge is necessary. In those cases, treat the LLM-judge as any other machine learning system and split your human-labeled data into train, development, and test sets for iterative development and validation. Here training data includes examples that might go in the judge’s prompt, development data is what the judge is iteratively modified to maximize true positive and true negative rates on, and test data is used to estimate the true performance in production. Over time as data drifts these evaluators will need to be updated. But regardless of whether you use programmatic or LLM-as-judge evaluators, you are still going to need some manual human-in-the-loop evaluation.
Don’t settle when it comes to evaluation tools
No one knows your problems better than you. So why use someone else’s generic annotation setup when manually labeling? That was one of the consistent messages from not only Hamel and Shreya but also guest lecturers like Dr. Chris Lovejoy of Anterior who spoke about a custom annotation setup he had built for medical applications. Compare the images of a generic trace viewer vs the one he built. It is so much easier for doctors to get the context of what is going on in the latter, and they can provide helpful labeling without nearly as much typing.
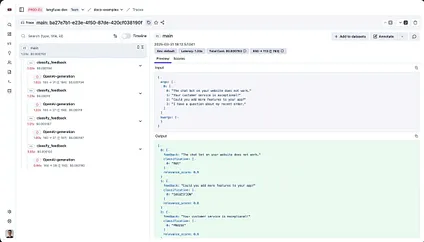
Screen capture of LLM trace examination in Langfuse from Chris Lovejoy’s talk
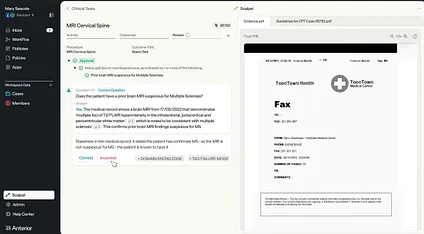
Screen capture of Anterior’s annotation interface from Chris Lovejoy’s talk
The best thing about these custom interfaces is that you can use AI tools to build them! Ask a coding agent to create suitable visualizations of inputs and outputs, add the ability to search and filter by cluster, and put in keyboard shortcuts Others have written about the potential for new AI systems to improve the speed of AI research, and I am a believer after seeing Shreya use Claude Code live to build an annotation interface in less than an hour. It is a perfect use case since annotation tools are usually internal-facing and are not super complicated.
Course details
Format:
All meetings were done over Zoom with Discord used for keeping track of Q&A. This caused me to constantly context switch between the two, and I hope they find a solution for this. While my classes were recorded live, future cohorts will just get recordings for the lessons with more instructor time spent on office hours and answering questions in Discord instead.
There were 8 course lessons, 7 office hours, and 15 guest lectures. Course lessons and office hours were an hour long and guest lectures varied from half an hour to a little over one hour. Everything was packed into four weeks. I also received a 150 page course reader that was essentially a draft AI evaluation textbook.
Price:
After the discount offered in the blog post, the course cost 3,000, but if you use the referral link here you will receive a 30% discount.
Audience:
The title says “engineers and PMs”, and tech sector engineers and PMs are mostly who I saw. But that is a little reductive. The core lecture content did not require the ability to code (though you did need to for the homework), and I think anyone who is making decisions based on claims about AI performance could benefit. I was joined by over 500 other attendees with a previously run cohort in June attracting 700. You can expect your classmates to ask many highly detailed questions in office hours and on Discord.
The next course starts October 6th. If you want to make the leap to evaluation-driven AI engineering, I highly recommend enrolling!